Use the command line to create a new directory called lab25 in your labs directory. Make sure all of the .py files that you create for this activity are in that directory.
Histograms allow us to visualize the distribution of some data set. For example, We could visualize the distribution of the birth months of children:
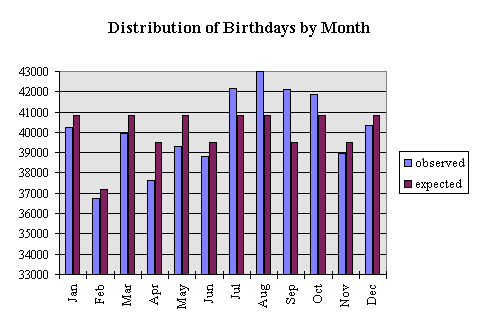
Where the purple bars are the expected distributions based on month lengths, and the blue bars are the actual, observed distributions from some data set. In a previous lab, we had the opportunity to use this information to change the probability distributions for computing the birthday paradox. Today, We will generate a histogram that could possibly be used to break a substitution cipher.
Details
Create a function called print_histogram(text) in a
file called histogram.py. The function should print a
sorted (in descending order) histogram that represents the number of
occurrences of the characters in text. You will use a
dictionary to represent this histogram, with the keys of the
dictionary as characters and the values of the dictionary as
integers.
Sample Test Cases
| Function Parameters | Expected Output |
|---|---|
| hello |
l: ##
h: #
o: #
e: #
|
| This is a test! |
s: ###
: ###
i: ##
t: ##
T: #
h: #
a: #
e: #
!: #
|
Hint
-
Create a function called
compute_histogram(text). The function should return a dictionary that represents a histogram of the number of occurrences of the characters intext. The keys of the dictionary should be characters and the values of the dictionary should be integers.You are going to follow the accumulator pattern for this activity. However, you aren't going to have a single accumulator. You are going to have multiple accumulators all stored in a dictionary. This dictionary is your histogram that you are going to return.
The for loop should iterate over the characters in
text. For each character, increment the value of the character's entry in the dictionary. Note, you must handle the special case of the character not already having an entry in the dictionary. -
To print the histogram in descending order, first find the entry with the largest value in the dictionary. Use the dictionary
valuesmethod and the built-inmaxfunction to find the largest value.Create a function
reverse_lookup(dictionary, value)that returns the key of an entry indictionarythat has the valuevalue. Note, there may be more than one key with the specified value, in this case it doesn't matter which key associated with the value is returned.Use the
reverse_lookupfunction to print the character with the largest value in the dictionary. And use the*operator to print the appropriate number of#characters. Then use thedeloperator to delete the entry from the histogram dictionary. Repeat this process for the next largest value until the dictionary is empty.
Challenge
A substitution cipher is a non-linear cipher that relies on a "look-up" table (the key for the cipher) in order to accomplish the encryption. It avoids the problems of the Caesar cipher, because the mapping from plain-text character to cipher-text character is not a linear function; you have to figure out each character individually in a substitution cipher.
If something is known about the plain-text, we can make an attempt at figuring out the entirety of the mapping. Suppose it is known that the plain-text was written in English. We know the distribution of characters in the English language:

If we take the most commonly occurring character from the cipher-text, chances are it is the encrypted version of 'e'. The second most common character is probably the encrypted version of 't'. The third most common is probably the encrypted version of 'a', and so on.
You are provided with the
module ciphers.py,
which includes functions encode_substitution(plain_text,
key) and
decode_substitution(cipher_text, key, ordered). Create
a program in a file called
hack_substitution.py. This program should read in a
cipher-text string, and attempt to decode the string using the
sequence of the most commonly occurring characters. Try your
program on this
encoded file. You can redirect a file to your program by using the
"<" operator at the command line.
$ python3 hack_substitution.py < encoded.txt
How well does it work? Can you at least read some words? Why does this not work out exactly correctly?
Submission
Please show your source code and run your programs for the instructor or lab assistant. Only a programs that have perfect style and flawless functionality will be accepted as complete.