Yesterday in class, we discussed a new type of data structure called a "Tree." Trees give us a hierarchical mechanism for storing data. Today in lab, we will implement a specific class of Tree, referred to as Binary Search Trees.
The file binary_search_tree.py contains a very sparse outline for a creating a binary tree. Recall that each node in a binary tree contains at most two children: a left child, and a right child.
What separates binary search trees from normal binary trees are how elements are stored within the tree. Normally, there are not any restrictions on where data can be stored within the tree. In a binary search tree, we will impose some ordering among the elements:
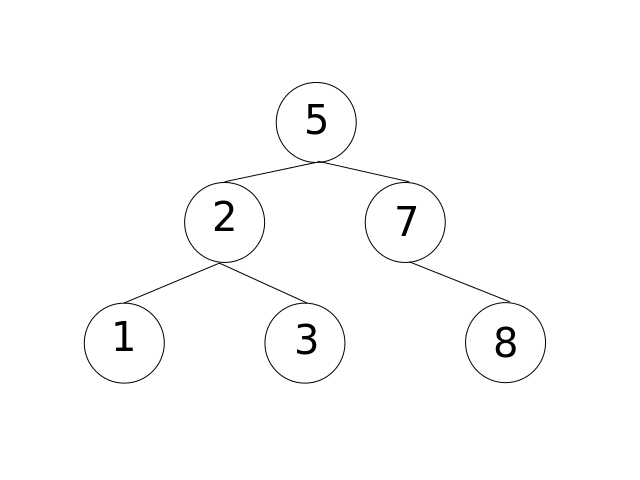
The above tree is a binary search tree. Consider the root of the tree "5." All descendants in the left side of the tree are valued less than "5." All descendants in the right side of the tree are valued greater than "5." We refer to the tree rooted at the left child as the Left Sub-tree. The Right Sub-tree is the tree rooted at the right child.
You should write your insert method such that it
enforces the above conditions. You should first create a tree node
for the new data. Then you should find the location to put the new
tree node. If the root is None, then the new node becomes
the root. Otherwise, compare the data you are adding to the root.
value of the new data is less than that in the root, the value
belongs in the left sub-tree. If the left reference
is None, then this node becomes the new left child.
Otherwise, get the node at the left child, and attempt the same
process again.
Use a similar process if the new data is
greater than that in the root.
Before you continue, you should test your insertion code thoroughly. How can you verify your insertion code works?
Right now, it is pretty difficult to get a visual representation of a tree. To remedy this situation, you can draw the trees you generate by hand. The file test_binary_tree.py contains three test trees. For each of the test trees, draw out (BY HAND! ON ACTUAL PAPER!) what the resulting trees would look like. Hand your hand drawn trees in at the end lab.
Your hand drawings will be useful for testing your code. Add some print statements to your insertion code, and try to build the trees contained in the above code. Does it seem like the trees being generated match your drawings? We will produce a more visual representation of the tree later, but for now you should be able to create some argument about the correctness of your insertion code.
You can easily test your code above by hand, but it is easier if you can produce some string representation of the tree. One mechanism for generating these strings use techniques known as tree traversals. As we discussed in class yesterday, there are two different approaches to traversing a tree: Breadth First and Depth First.
print_depth_first contains the code we discussed at
the end of class yesterday. It uses
a stack
(and the stack "interface") to keep
track of what elements it should be printing next. This method
prints out a representation of the tree by fully exploring one path to a
leaf in the tree, and back-tracking to explore all other paths to
the leafs of the tree.
Breadth first traversals are very similar to the depth first code listed above, but the results are quite different. Breadth first traversals require using a Queue, which you wrote last week in lab. It starts by adding the root to the queue. You continually dequeue a node out of the queue, and print its data. Then, add both children (in some arbitrary but consistent order) to the queue. This continues until you have visited every node in the tree.
Draw a sample binary tree, using letters as the values stored
within the tree. What string should the above algorithm produce?
After you have written out this test case, go ahead and code this
algorithm in print_breadth_first. This
method should print a representation of the tree using the
above algorithm. Does your algorithm meet your expectations?
There are actually three types of depth first traversals. They
are preorder, inorder, and postorder. All three of these depth
first techniques can be written using the implicit system stack,
by using recursion. As you can see
in binary_search_tree.py, each of the depth first
techniques requires the root of the tree that is being traversed.
In each method, you will recursively call the traversal technique
on each sub-tree. The only difference between the three are where
you actually print the data.
Preorder traversals print data when you first visit a node. This
is accompished by printing the data in the current root before you
recursively call preorder on either sub-tree. Inorder prints all
of the elements in the left
sub-tree before printing the data in the current root. Postorder
prints all of the elements in both sub-trees before printing the
data in the current root. Finish the code
in print_in_order, print_pre_order,
and print_post_order.
Test the above methods. Which traversal technique makes most sense for the test case that you generated before writing breadth first traversal? Which makes the least sense? Can you easily infer the structure of the tree given the output and the traversal technique used?
You are now able to create binary search trees. Now, how do we figure out if an element is contained within the tree? Consider the tree above. Given the root of the tree, we know that all values in the left sub-tree are valued less than the root, and all values in the right sub-tree are valued greater than the root. We can use that information to determine where to continue searching for the requested value.
For example, If we were looking for the value "3", we know that it MUST be a descendant of the root through the left child. We can continue searching from there, using the node valued "2" as the new root.
The algorithm for searching in a binary search tree is as follows:
Let D be the value we are searching the tree for.
If the value in the node you are currently exploring is
D, then return true, as you have successfully found the
element. Otherwise, if D is less than the current node, then
move to the left child, and repeat the process. If D is
greater than the current node, then move to the right child and
repeat the process. If you ever reach a node that
is None, then D is not in the tree and you
return False.
Write this algorithm up in the method called search.
Will this algorithm always produce valid results? Does it work on
the Trees you generated in the first part of this lab? Make sure
you test this algorithm before moving on to the next part.
What is the Big-O complexity of the above search technique? Does
this algorithm remind you of another algorithm we have used before?
Write up your analysis in a file
called search_complexity.txt, and include it in your
submitted zip files.
Submit a zip file of your code on the course Inquire site that uses your last names as the file name. Don't forget to turn in your tree drawings!